Dell Research Library.
Turning thousands of scattered research artifacts into a findable, reusable, company-wide asset. A custom cloud platform a small team and I architected, shipped, and iterated from alpha to v1.5.
Dell had decades of research, and no way to find any of it.
Dell generates enormous amounts of customer evidence every year: interviews, diary studies, ethnographies, surveys, heuristic audits, competitive analyses. Two decades of it was scattered across shared drives, SharePoint, personal laptops, and the memory of whichever researcher originally ran the study. The result was predictable. A PM in Round Rock would commission a $40k study to answer a question that had been answered three years earlier in Hopkinton. I didn't want another taxonomy. I wanted infrastructure.
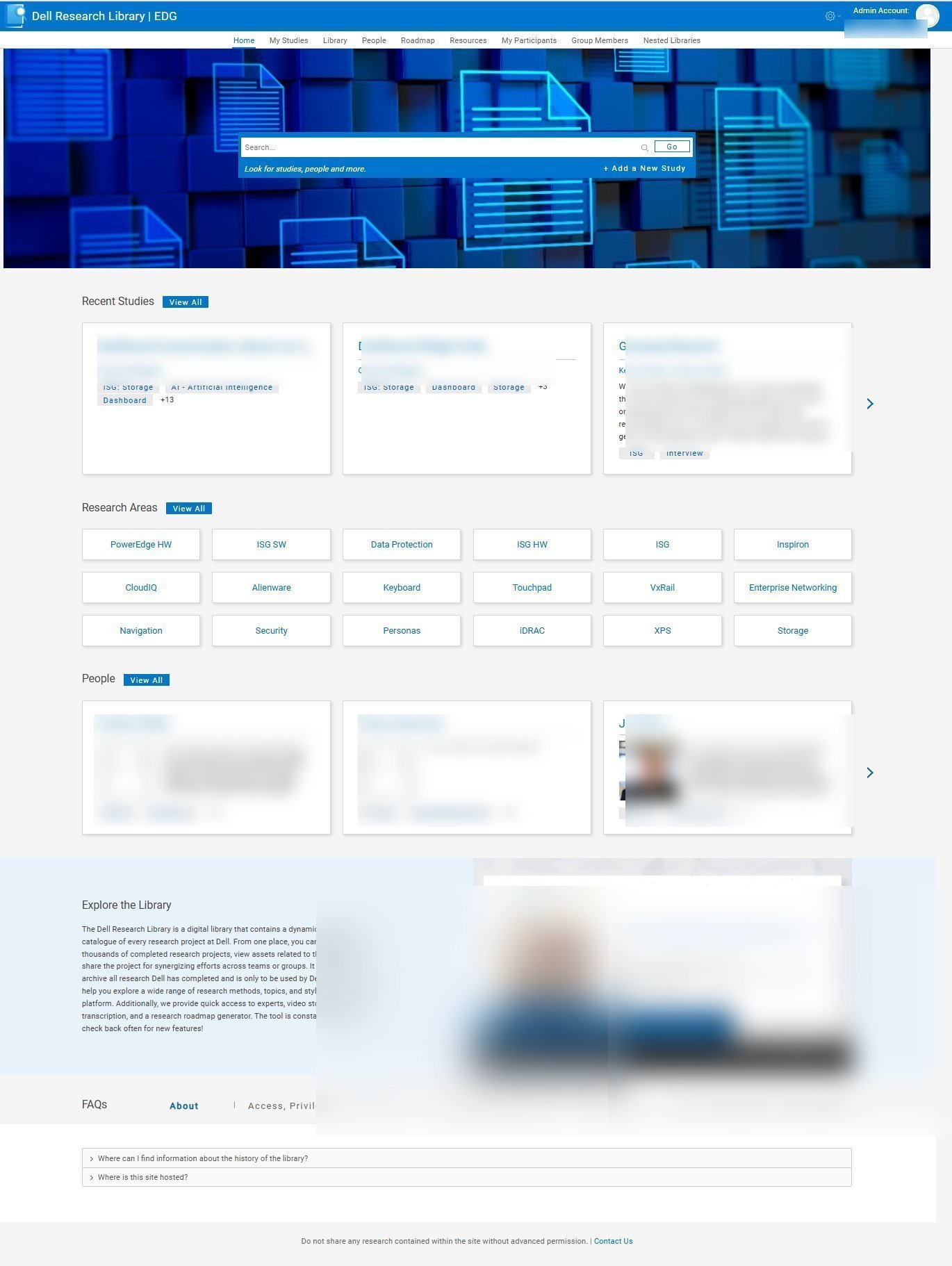
The goal was never to archive research. The goal was to make every study that Dell had ever conducted behave like a living, queryable asset, something a designer in Taiwan or a PM in Austin could interrogate at 2am and get a useful answer from.

Treat research as a platform.
My technical background (a decade of cloud, virtualization, and distributed systems work before I ever managed a designer) shaped the first instinct. This wasn't a cataloging exercise. It was a software product with users, data, ingestion, retrieval, and a long roadmap.
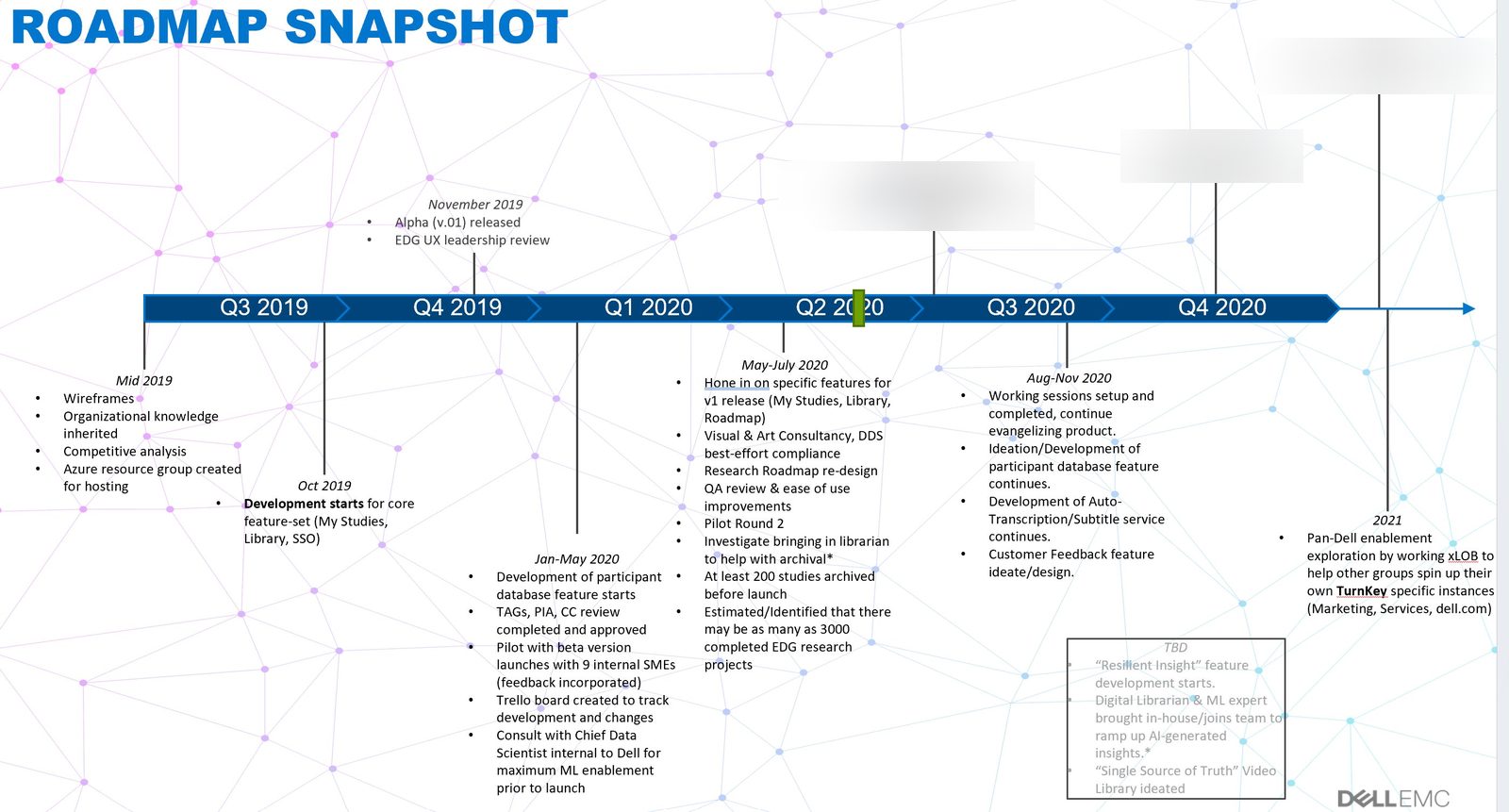
A.01Research the researchers
Before a line of code was written, we ran a cross-LOB discovery with eighteen research consumers (designers, PMs, engineers, services leads, executives). The failures clustered around three things: taxonomy they didn't understand, file formats they couldn't preview, and findings buried in 90-minute videos with no transcript.
A.02Architect for retrieval.
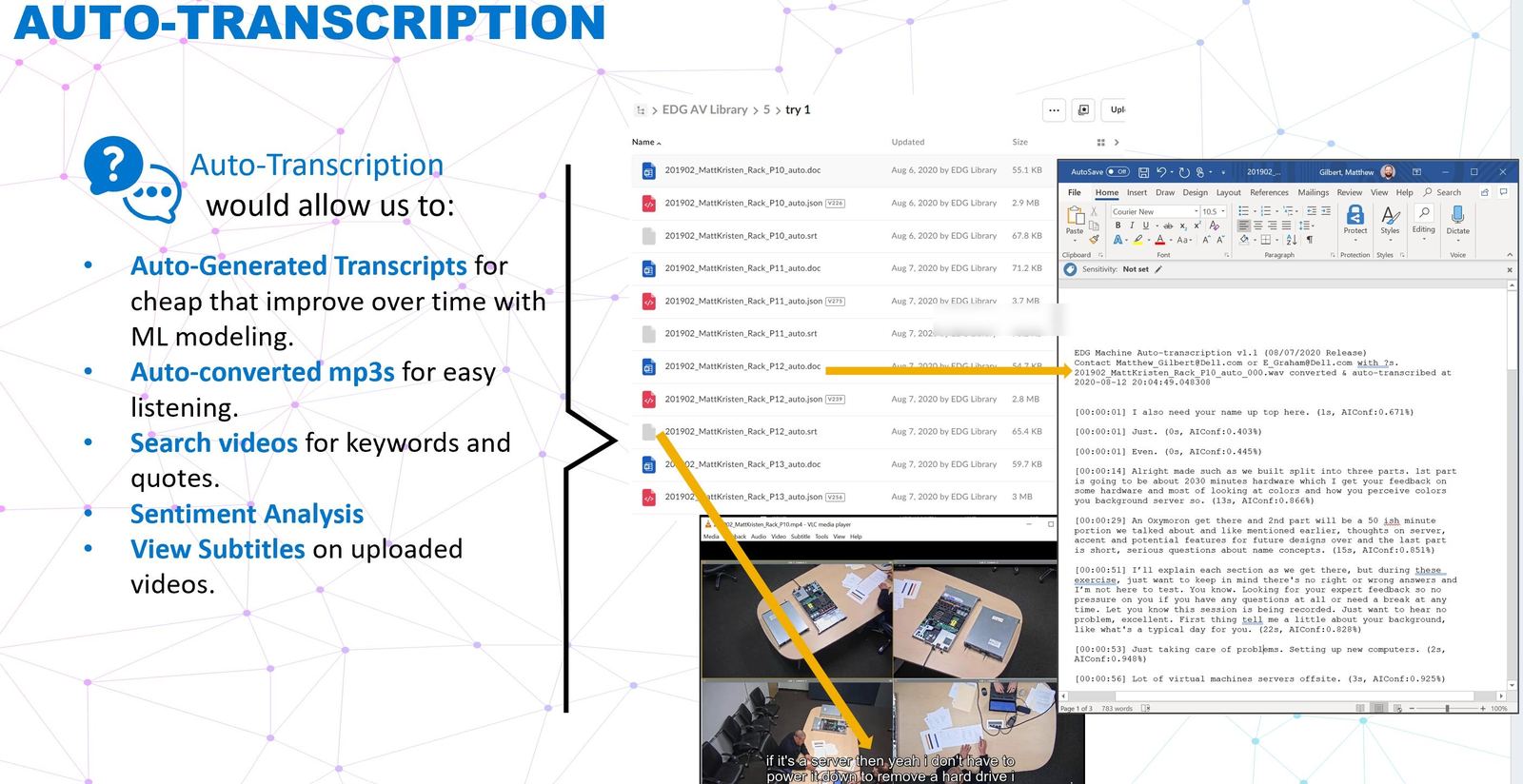
That insight reshaped the system. We designed around the moment of recall, not the moment of upload. Auto-transcription on every video asset. Machine-readable tagging against a controlled vocabulary we authored with the research team.
A.03Ship small, ship real
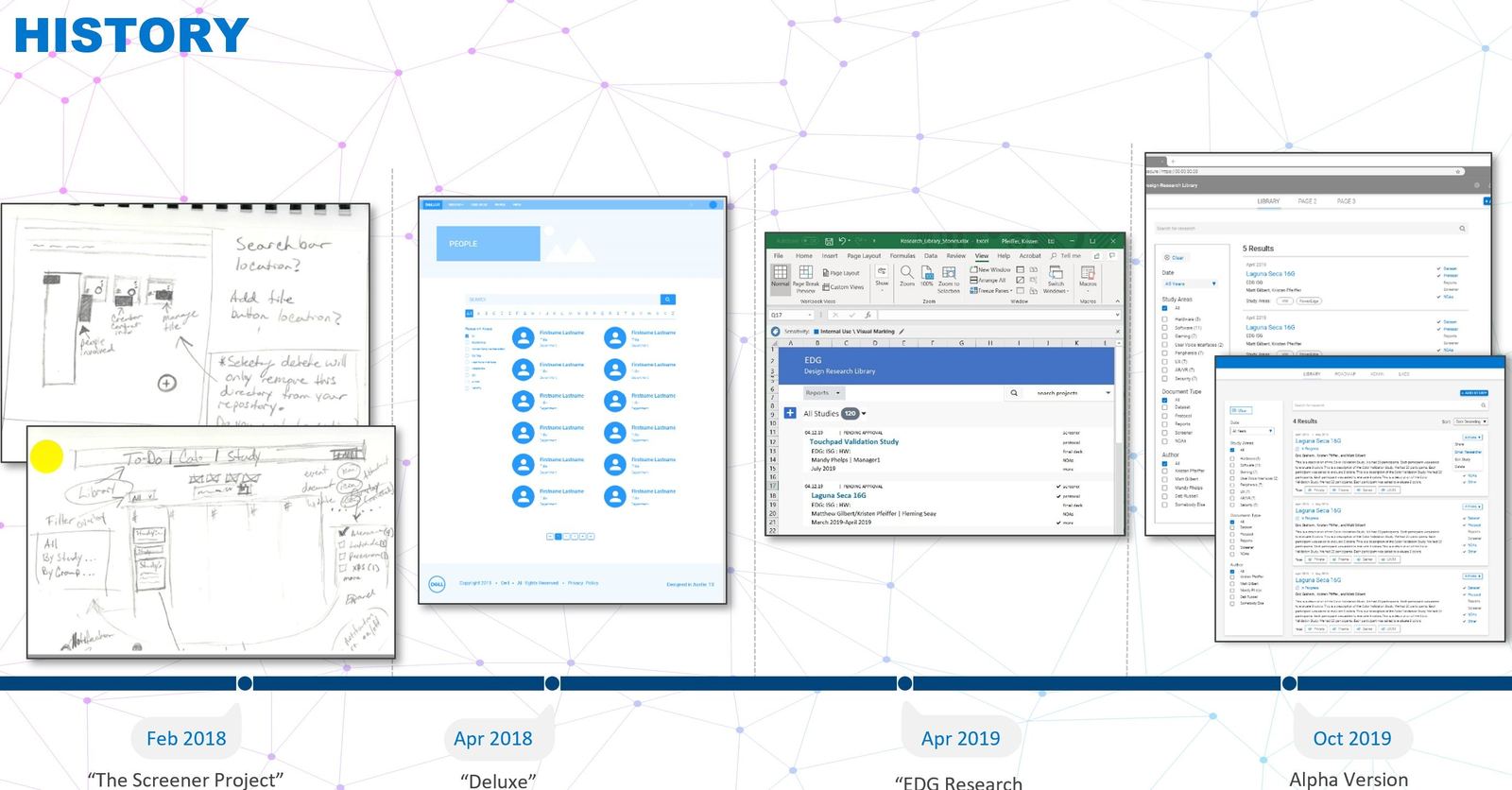
Alpha launched internally with a single LOB and about 200 studies loaded. By v1.5 the platform was serving the full company footprint, and researchers were voluntarily reaching for it, the truest signal a tool has crossed into useful.

Four capabilities that turned a repository into a platform.
Auto-transcription on everything.
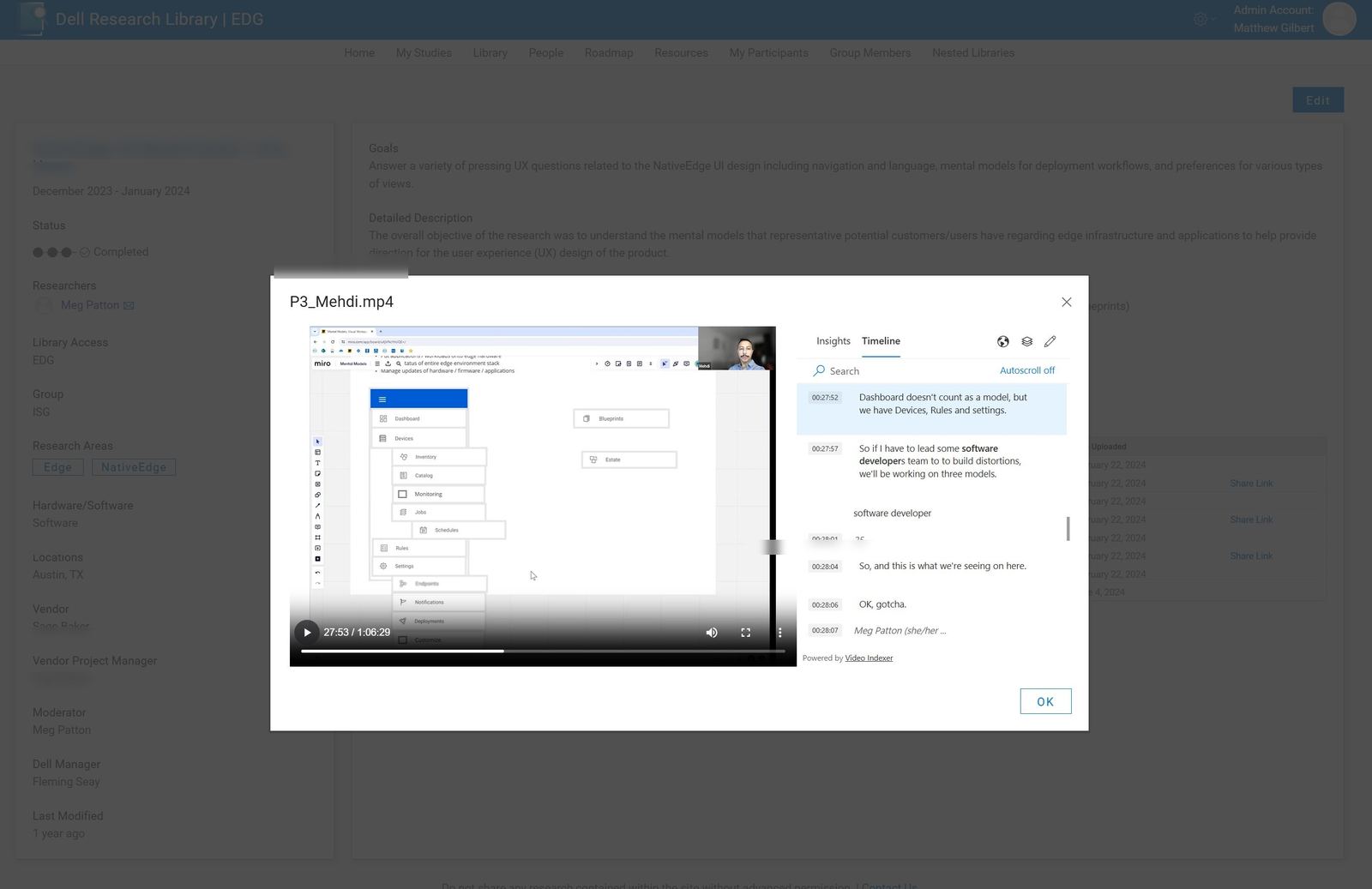
Every video asset ingested is transcribed, time-coded, and made full-text searchable. A PM looking for "thermal complaints" can jump to the 47-minute mark of a 2019 interview in two clicks.
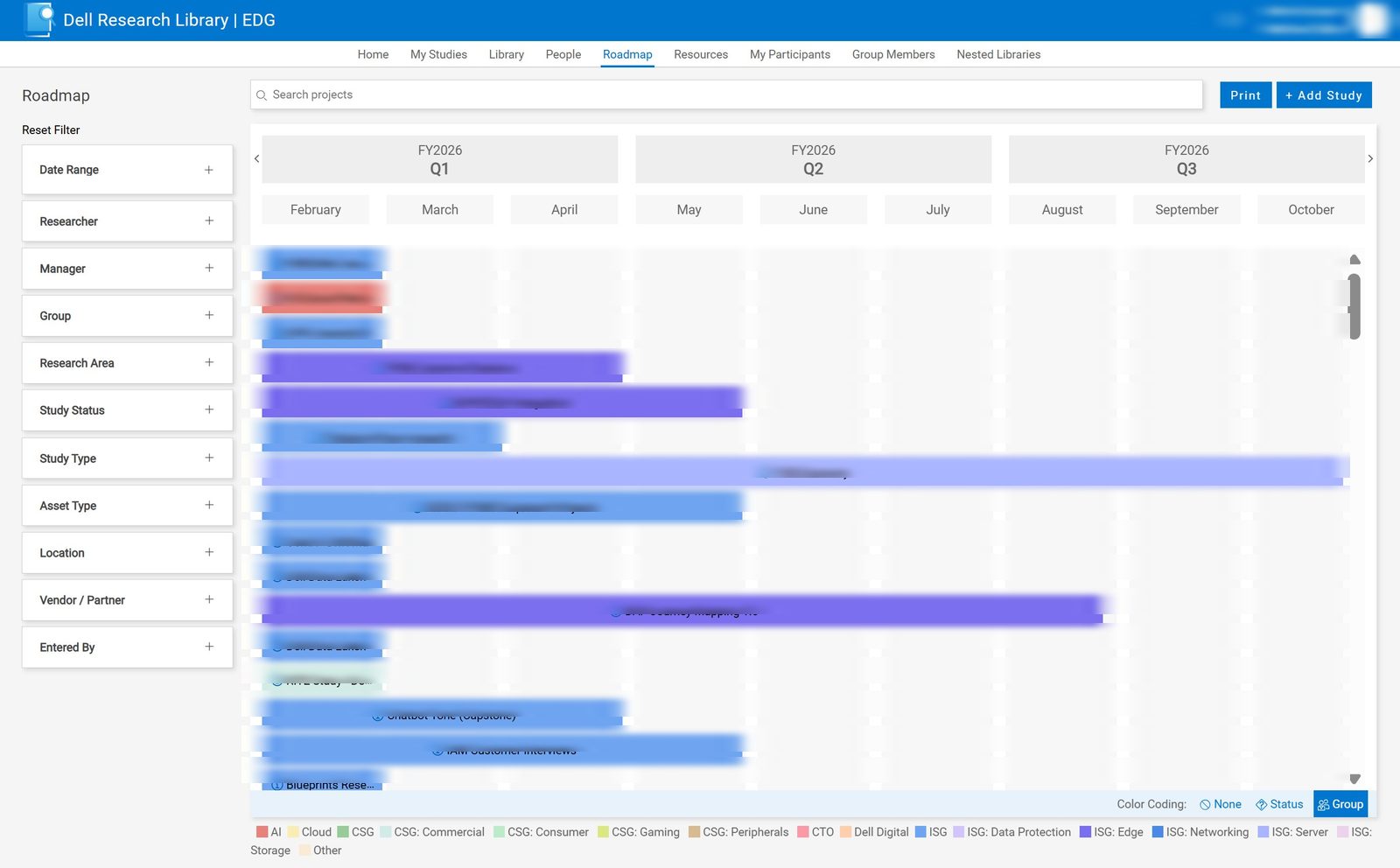
Study tracking & roadmap generation.
Active research is tracked from intake to closeout, and the platform auto-generates forward-looking research roadmaps by LOB. Planning conversations start with evidence, not guesswork.
Controlled tagging & IA.
We authored a shared research taxonomy with the global team, then enforced it at ingestion. Retrieval quality is only as good as the vocabulary, so we invested there first.
Built for cross-LOB reuse.
Permissions, versioning, and citation live in the platform. A study conducted for one product unit can be cited, adapted, and re-used by another without losing provenance.
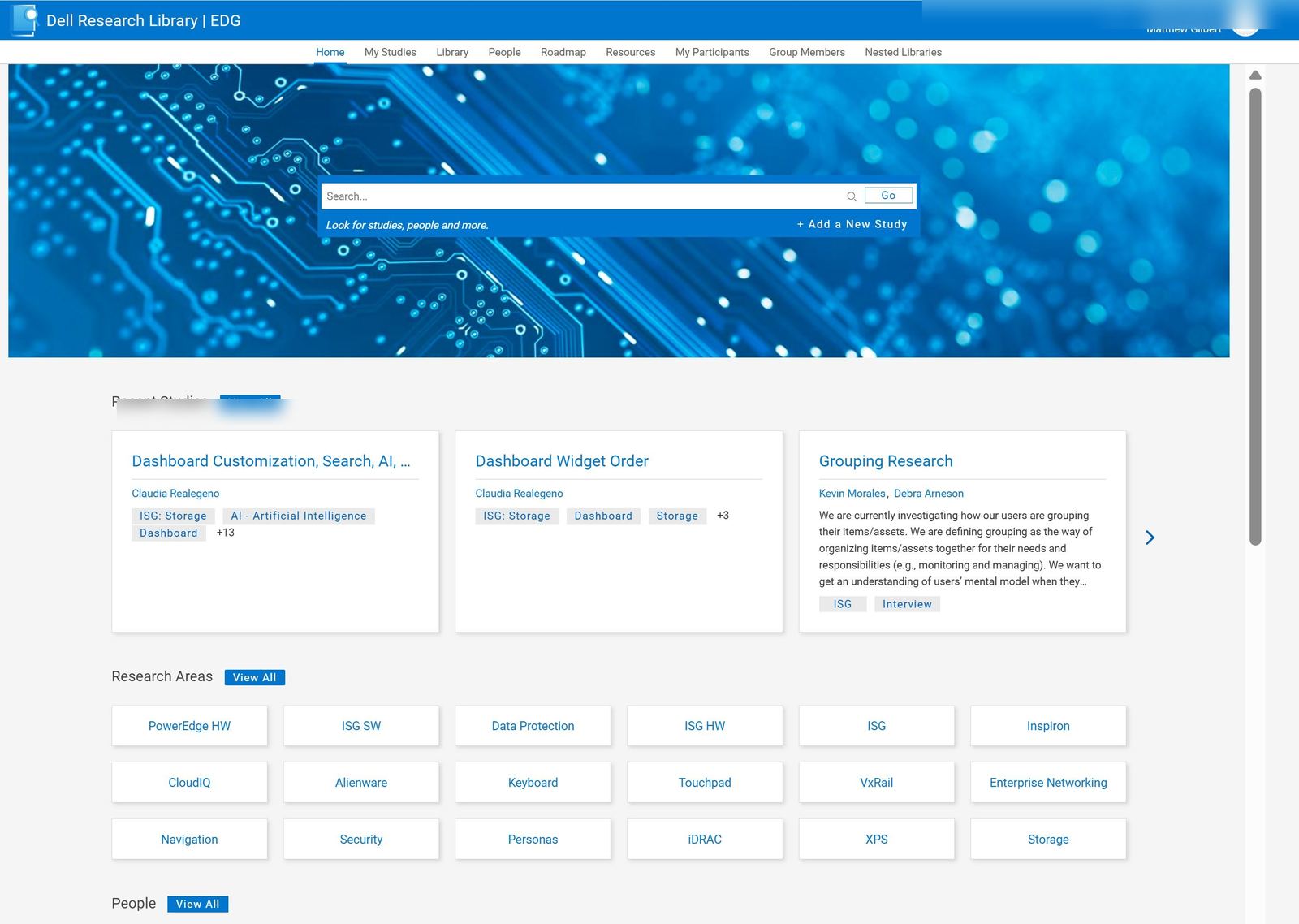
People used it.
The most honest measure of an internal platform is whether people reach for it when nobody's watching. By v1.5 they were. Researchers used it unprompted. PMs cited it in planning docs. Newly-hired designers used it to get up to speed on a decade of product evidence in a week. A study stopped being a one-off deliverable for a single stakeholder, and became something findable, citable, and re-usable.
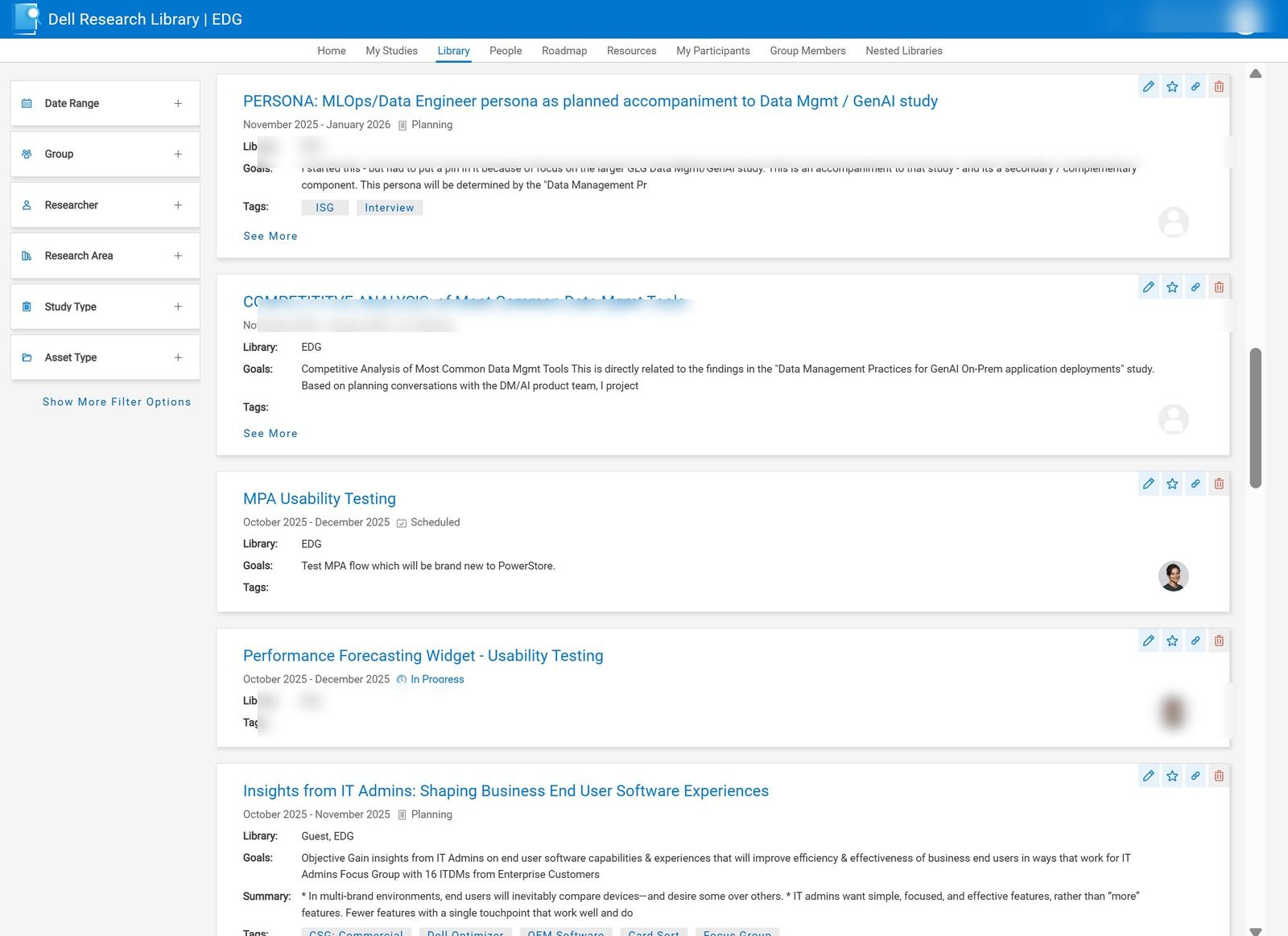
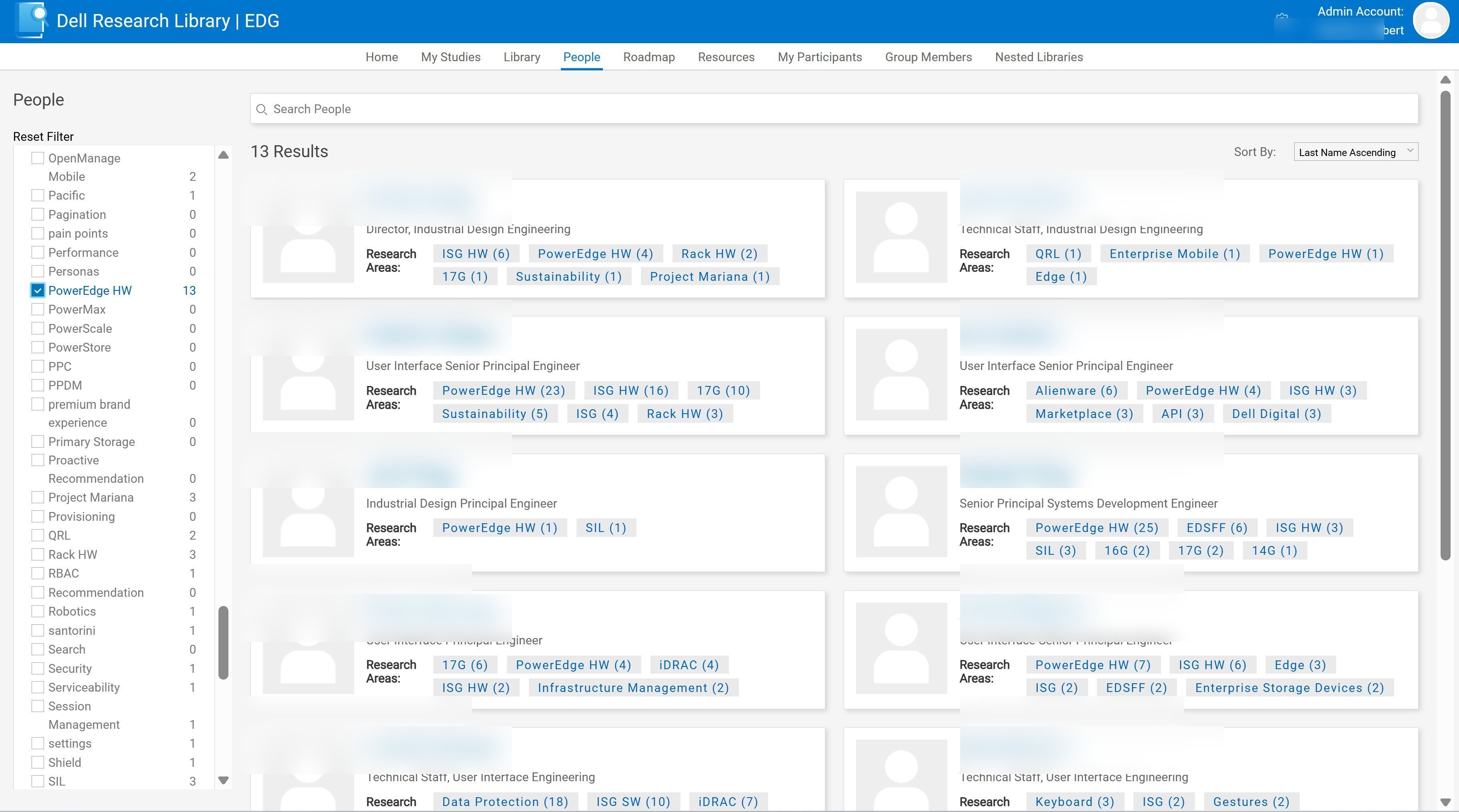
People-first search. For when you don't know what document you need.
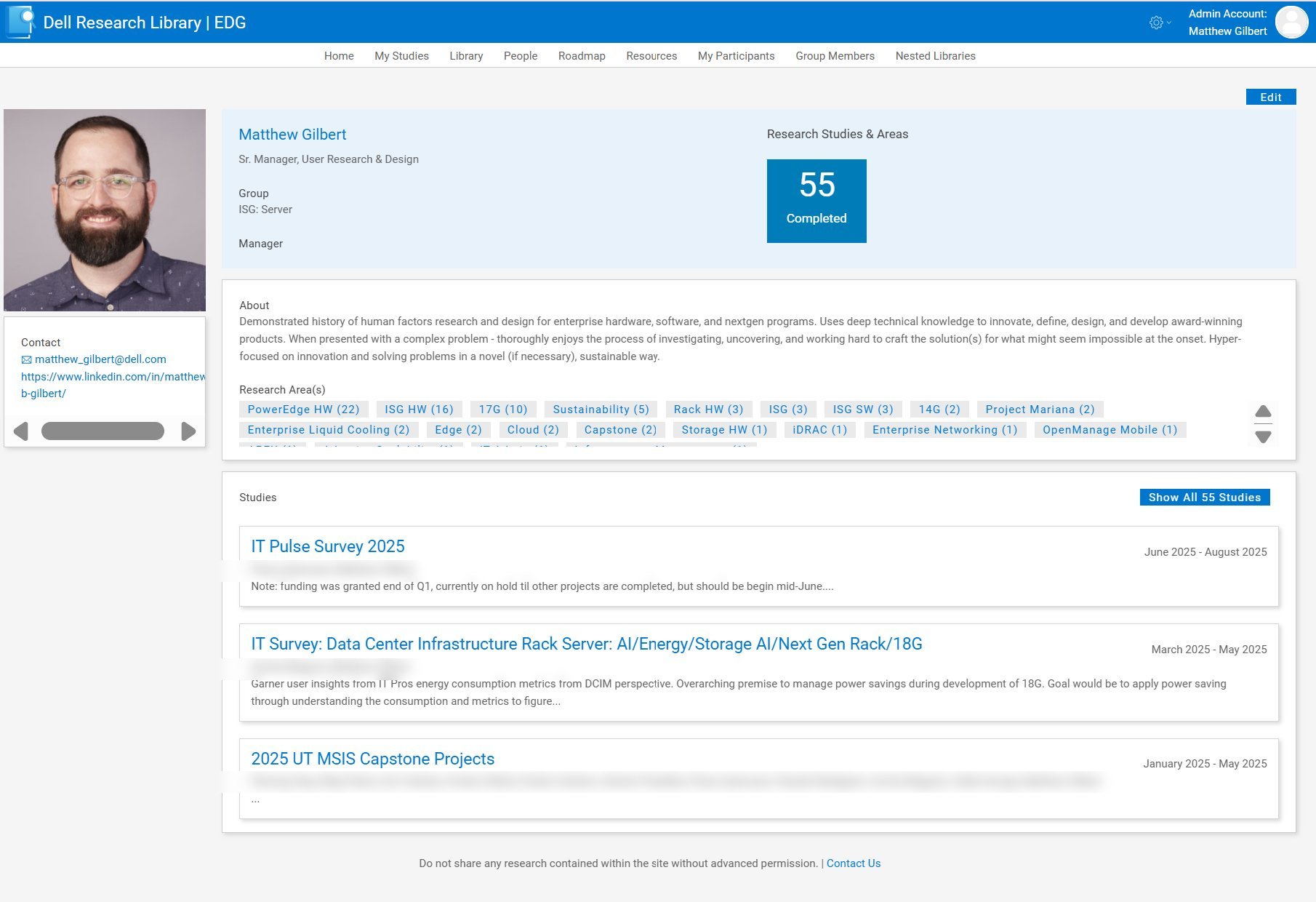
As a consumer of research, you often don't know exactly what you're looking for from outside a topic. So we introduced robust searching across experts. You could figure out who had done what work before, browse what they specialize in, and reach them directly. Each employee has a profile page that surfaces their full research history, the areas they've worked across, and how to contact them.
In 2022, we structured the corpus for ML retrieval. Two years before the LLM boom.
We worked with an AI data architect and ML expert in 2022 to structure the library's data properly ahead of time, so it could be ingested into machine learning when the moment came. That foresight has paid off in 2026: we can now model against the entire research catalog whenever it's needed. The structured-data foundation we put in place years before the AI wave is what makes that possible today.
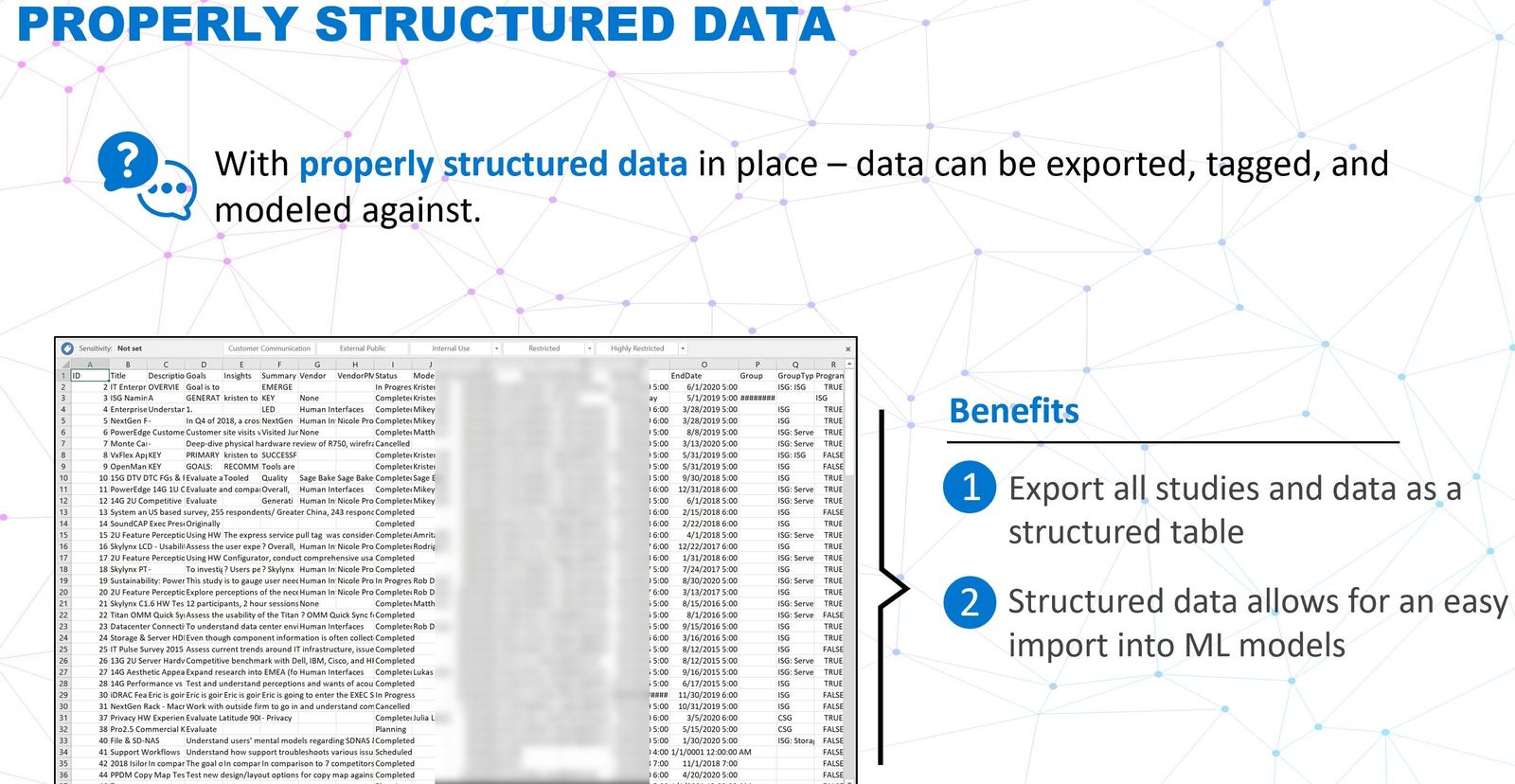
The corpus became training data.
A year or two in, something unplanned started to matter. Because every asset was transcribed, tagged against a shared taxonomy, and stored against a consistent schema, we had quietly built a clean structured corpus of Dell's research history, the exact shape modern AI systems need. A designer can now ask "have we heard this complaint before?" and get an answer grounded in a decade of real interviews. A PM can ask "what does the research say about this segment?" and get a synthesized view in seconds.
It wasn't the original goal. It's what happens when you build the data layer correctly the first time, the tools you'll want two years later find your data ready for them. It's also why the agentic AI work I'm leading inside Dell now has a running start most enterprises don't.
The Library stopped being just a research tool and became research infrastructure — and then, without anyone planning it, became the training layer for the next generation of AI-assisted research at Dell.