Synthetic personas, built to scale hypothesis & guardrail AI design.
A research-grounded synthetic-persona system. Built in weeks instead of quarters, used two ways inside Dell: as a hypothesis shortcut in front of real customer research, and as a guardrail for AI-generated design on an unreleased systems management product shipping later this year.
Persona governance lives in the model's request path.
The version of synthetic personas inside Dell is one half of a larger pattern. The other half is the guardrail layer that enforces persona use across the entire AI-driven design and engineering process. Three input lanes (PdM, Engineering, UX) feed the guardrail, and nothing reaches the model without going through it.
This is a proof of concept currently in socialization and rationalization. Below: the architecture at a glance, then the UX workflow fully unpacked since this case page is about the design side.
- P.01Check task scope against PRD
- P.02Look for product policy / OKR alignment
- P.03Validate against business constraints
- E.01Check task against architecture rules
- E.02Look for tech-debt context
- E.03Validate output against constraints
- B.01Persona fetch & fallback chain
- B.02Clarifying questions
- B.03Output validation against persona
- B.04Drift detection
- B.05Multi-persona conflict resolution
- check task scope
- component / feature / UI
- look for persona.md
- human-authored: use as-is
- synthetic: use, log version
- if none found
- generate from internal repo
- else: external research + rules
- no persona = block call
- before output, prompt user
- role / seniority context
- primary task right now
- tools already in use
- org / team scale
- persona seeds the question set
- enterprise IT pro = security-first
- SMB admin = cost-first
- skip = degraded output flag
- validate before returning
- claims match persona context
- vocabulary fits user level
- workflow plausible in real env
- score against rubric
- pass: return
- borderline: flag, return
- fail: regenerate w/ stronger system prompt
- monitor output across session
- vocabulary drift
- workflow assumption drift
- tooling fictional / hallucinated
- if drift > threshold
- re-inject persona
- notify designer
- repeat drift = pause session
- check for overlapping personas
- primary user vs admin user
- end-user vs decision-maker
- resolution order
- task scope (whose goal?)
- access level required
- explicit override (PM/PdM)
- unresolvable = clarifying Q
The output of the guardrail isn't just a validated response. It's traceable, loggable, and observable. Every reply records which persona was used, which branch fired, whether validation passed, and what got flagged. That trace stream feeds the auxiliary persona library so any employee can see which personas are getting exercised in production AI work, and which are being asked to do too much.
It's the difference between a guardrail that hides its work and a guardrail that teaches and governs.
Persona work at enterprise scale takes time to get right, but the lack of personas in a program leaves a significant UX gap.
Real customer research is slow and expensive. Twenty-five deep interviews across five verticals take six months and six figures, and still only cover a landscape moving faster than our calendars. Meanwhile, new programs are popping up every month with MVPs expected to launch in months, not years. Engineers can spit out good-enough (for leadership) design to keep the product concepts moving without time for UX check-ins. The question that interested me, and drove this proof of concept: is there a form of synthesis that sits honestly between those two extremes? Can we introduce a process that injects the human in the loop? Can we have it work alongside our design system as a peer?
A research-grounded companion to our design system.
If every claim has to cite a real, recent, named source, and the hierarchy is enforced by tooling rather than willpower, the output stops being "AI-generated content" and becomes "AI-generated synthesis of real research." Different thing. Five rules, in order of how much they matter.
A five-tier source hierarchy.
First, real research completed by real researchers. If it exists, that is the source of truth. Next, regulatory and standards bodies (FERC, NERC, NIST, ISA, ECB, SEC, FINRA, CISA), then peer-reviewed academic work, then industry analysts, then vendor technical material, then trade press. When two sources disagree, the higher tier wins.
Nothing stale, nothing invented.
Nothing published before April 2024 unless it's a foundational learning or standard. The rule has teeth: claims that couldn't be sourced to recent, named research got cut rather than fabricated. Where exact numbers weren't available, ranges or qualitative directions were used instead of invented precision.
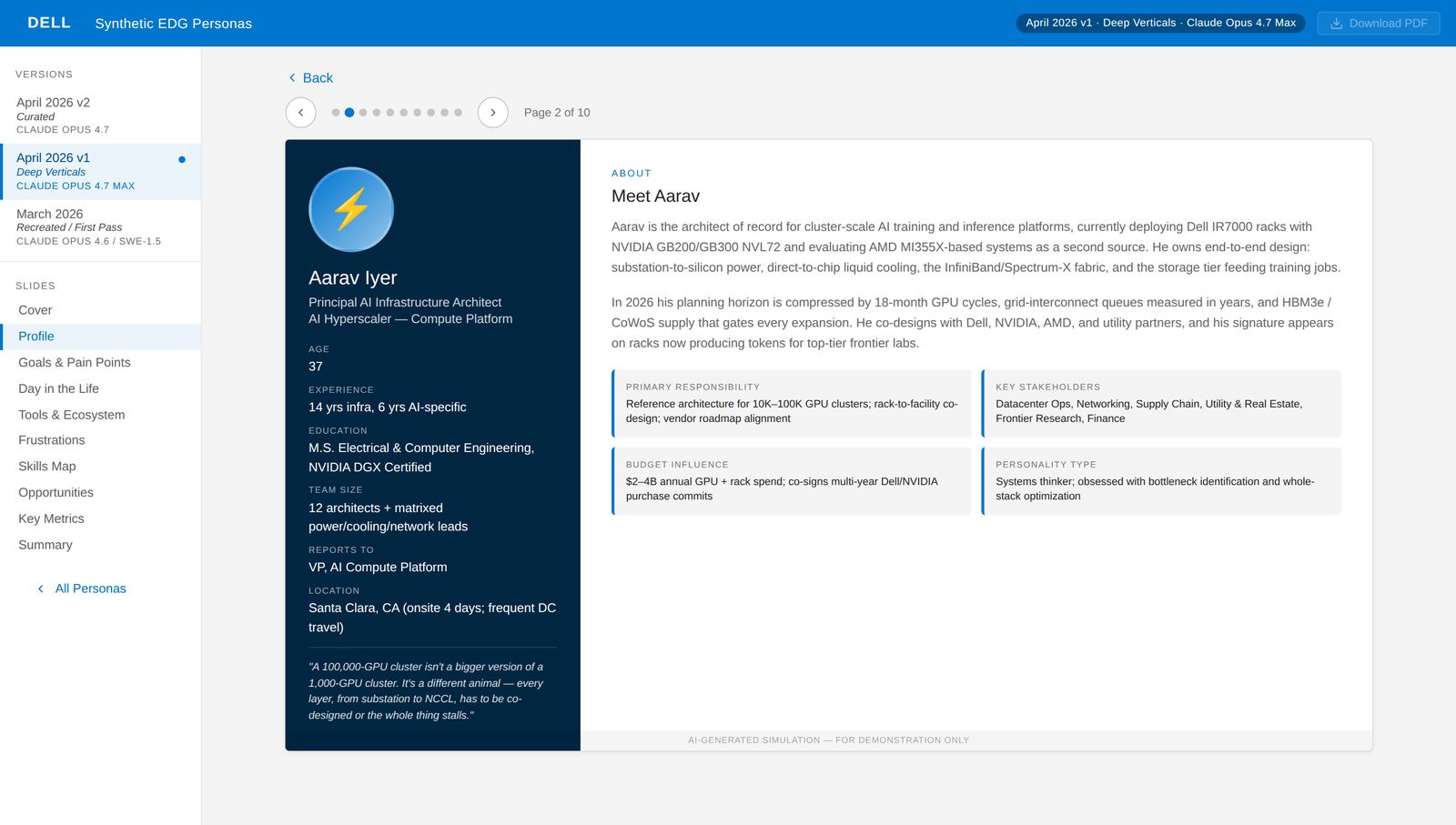
Every persona is the same object.
Every persona is a JavaScript object with ten top-level fields: cover, profile, goals, day-in-the-life, tools-and-ecosystem, frustrations, skills map, opportunities, metrics, summary. Same shape every time, which means the rendering layer doesn't care which persona is loaded and the authoring process can't quietly skip a section.
The validator is the point.
A Node-based validator runs as a permanent build step. Every metric card needs a value, a label, and a source. Every persona needs a needs array. Every nav category has to match one of the five verticals exactly. No duplicate IDs, no duplicate names across versions. When content drifts, the validator fails the build and nothing ships. Without it, the system is a pile of plausible text. With it, it's a data product.
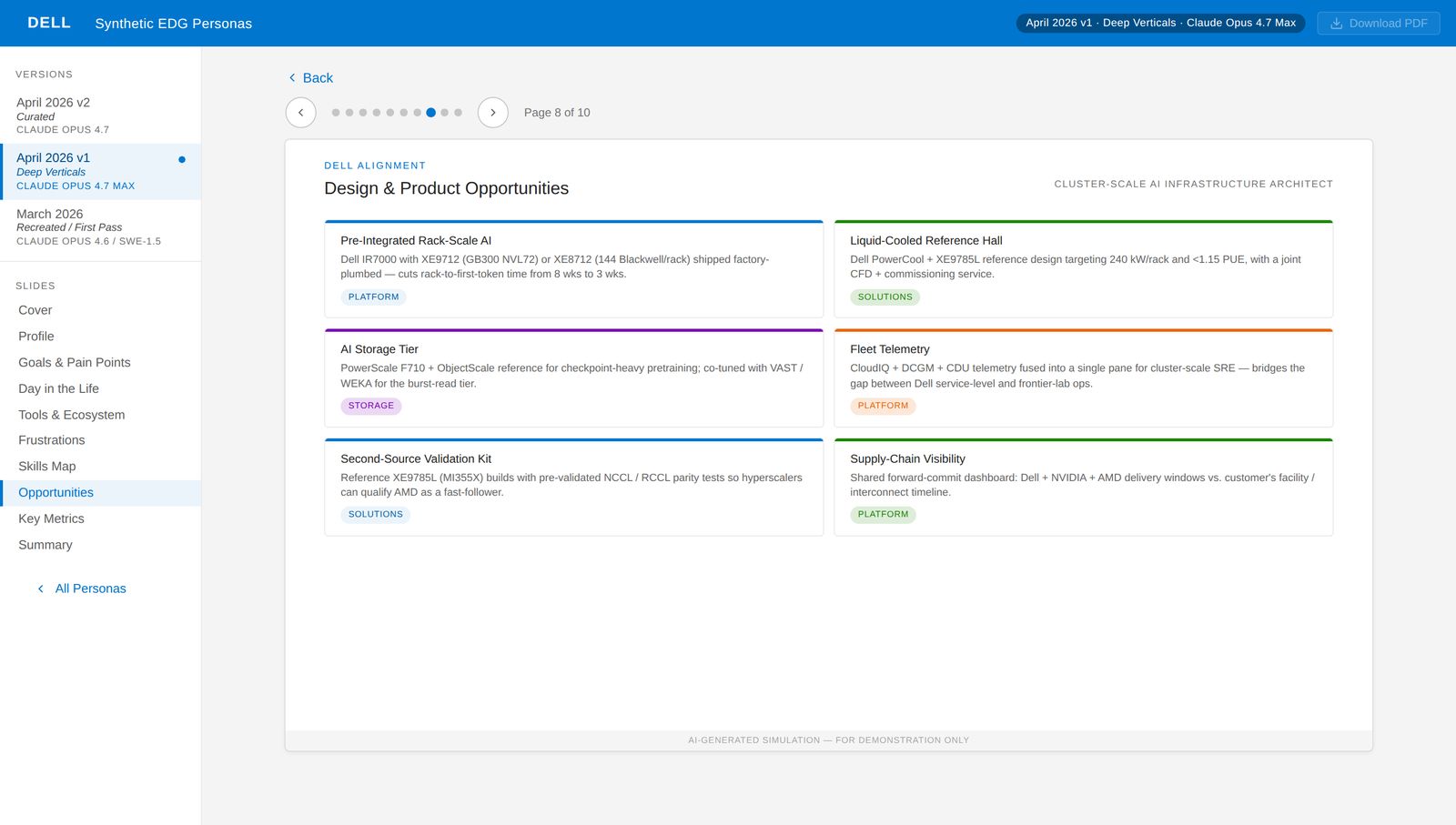
Dell SKUs, concretely.
Every persona's opportunities slide maps real needs to specific current-gen Dell SKUs. PowerEdge XE9712, XE9785L, IR7000 racks, PowerScale F710, PowerCool RCDU, CloudIQ, NativeEdge. No abstractions. If a persona would benefit from Dell's portfolio, the mapping has to be specific enough to act on.
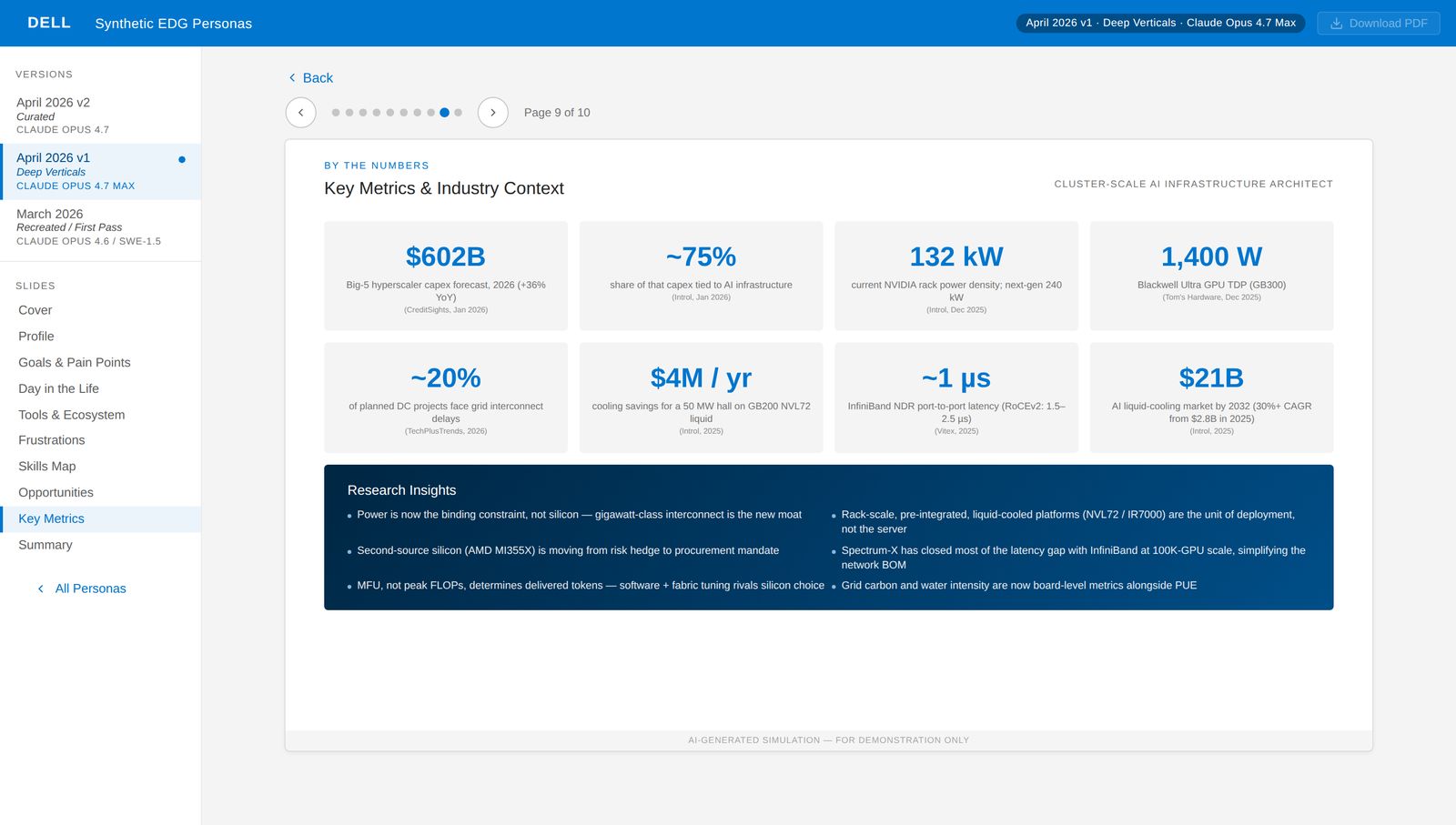
Robust, instant personas with evolving content to match program needs and the speed of delivery.
The depth is deliberate. A persona that gets three bullets gets used once in a kickoff and forgotten. A persona with twelve months of regulatory context, a realistic day-in-the-life, named vendor ecosystem, rated frustrations, skills map, product opportunities, eight sourced metrics, and a three-card summary becomes reference material teams come back to during detailed design.
Two uses in production. The second is why this matters for AI design.
First use: a hypothesis shortcut in front of real research. When a new product area needs persona coverage we don't have, we start synthetic to scope the space. What used to take four to six weeks of literature review and expert interviews now takes a sitting. The real research that follows is sharper because it's testing specific claims instead of discovering them. We can now develop proto-personas in minutes instead of weeks.
Second use: a guardrail for AI-generated design. On an unreleased Dell systems management product shipping later this year, the personas sit alongside the design system as a second input the AI layer has to satisfy. The design system governs visual and interaction grammar. The personas govern whether the output makes sense for anyone real.
AI synthesis fills gaps when first-party research isn't possible.
The value is in compressing time to a defensible starting point, and in making AI-generated design answer to something other than its own plausibility. The system is not a substitute for talking to real customers. Anyone using it as a stand-in for first-party research is misusing the tool.